I think that my ad room installation idea is ridiculously ambitious and it is unlikely that it’ll look exactly like the image in my head at the moment but i’m going to research and prototype some of the elements I might need to create it for at least a few weeks.
Keyword Identifier
Assuming that at some point I would have a device capable of doing live transcription of somebody in the installation room, I started tinkering with how I might select certain words transcribed by the system. These words would be purchasable commodities or themes found in advertising and would be passed to the image generation layer of the system. I think this would be necessary because if all of the transcription was passed as a prompt to the image generator, I think it would probably come out looking like mush.
The most obvious way is just to have some sort of lookup. If I could find a massive collection of things, or themes that have advertisements associated with them I could check each word against this list to identify keywords. A corpus for this could be the list of Meta Ad Topics, if I could find it.
I’ve used Word2Vec before for language analysis and thought I would try using it to identify words that I would want passed to the image generator.
sentence = "I want to go to the cinema and look at clothes."
testWord = "advertisment"
# Split sentence in to individual words, removing punctuation
sentenceWords = sentence.strip(string.punctuation)
sentenceWords = sentenceWords.split()
distances = []
for word in sentenceWords:
distances.append(word2vec.wmdistance(testWord, word))The ‘distances’ between each of the words in the sentence and advertisement were…
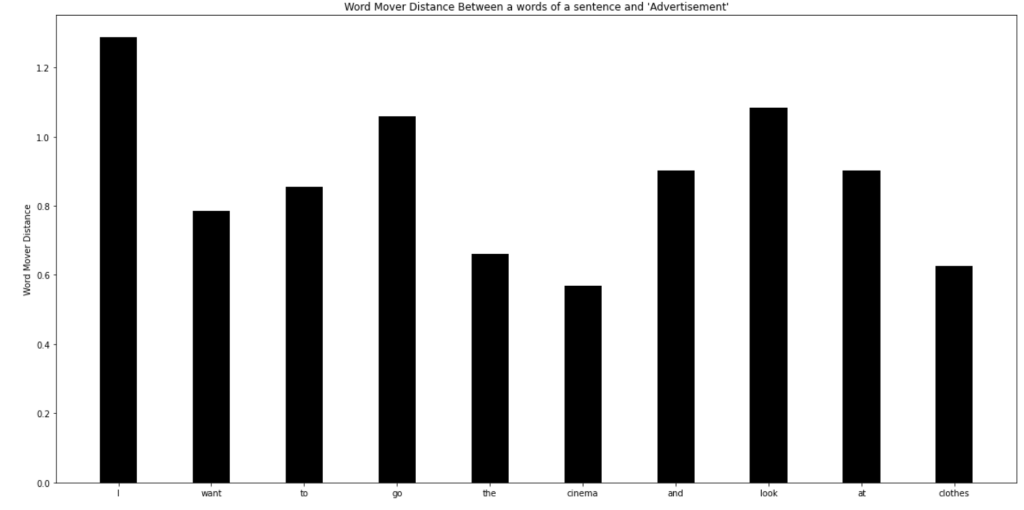
The two words I would consider keywords here are ‘cinema’ and ‘clothes’ as I feel like these could be seen in targeted advertisements. It’s encouraging that these seem to have the lowest distance but the system needs to be more robust.
First, a Kaggle notebook I was reading spoke about removing ‘stop words’ from analysed text. I think that if I continue comparing individual sentence words to another, single word rather than using n-grams, removing stop words will be beneficial.
Bibliography
https://www.kaggle.com/code/longtng/nlp-preprocessing-feature-extraction-methods-a-z